$ ./demos
▸ Desktop App (Beta)

▸ TUI (Terminal) Version
$ ./quick-start
▸ Desktop App (Beta)
Download desktop app · Releases
Look for keyless-desktop-* assets
# Download from releases page
# Install .dmg (macOS), .msi (Windows), or .deb/.rpm (Linux)# Build from source
Prerequisites: Node.js (LTS), pnpm (v10+), Rust, Tauri CLI
git clone https://github.com/hate/keyless.git
cd keyless/keyless-desktop
pnpm install
pnpm tauri dev # Development mode
pnpm tauri build # Production buildFirst run: Grant microphone and accessibility permissions when prompted. Download a Whisper model from the Models screen. Configure your hotkey and output mode in Settings.
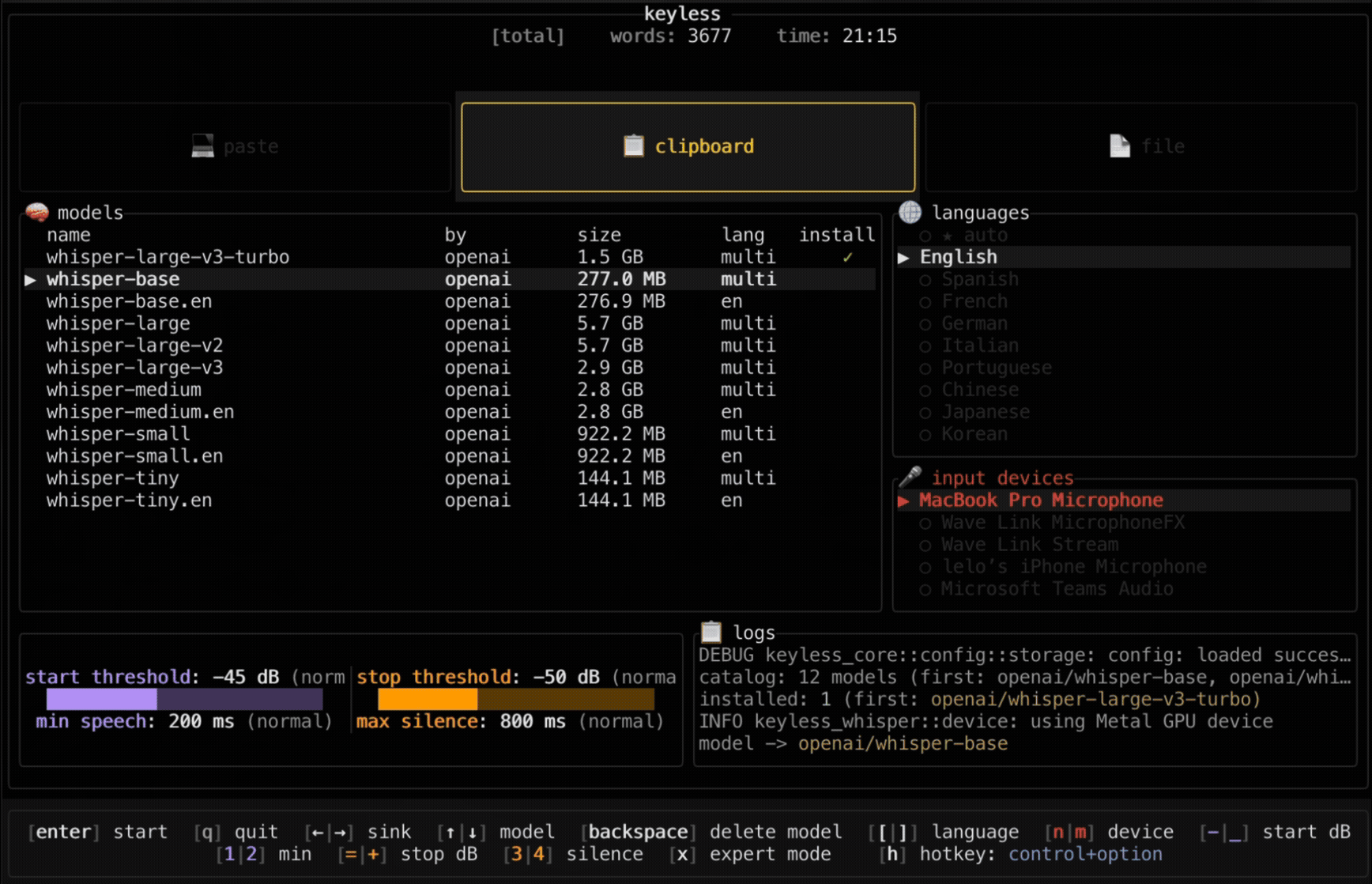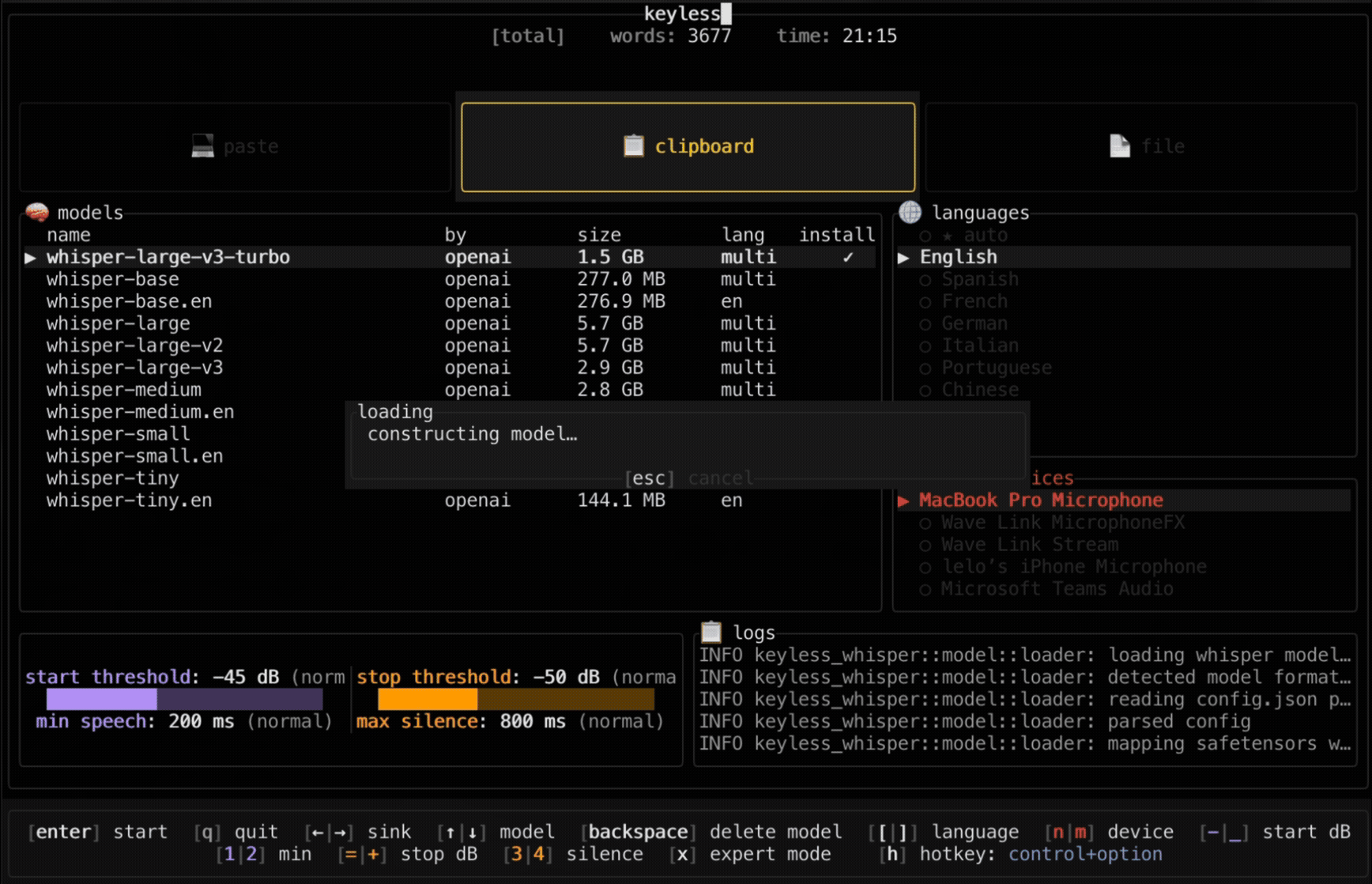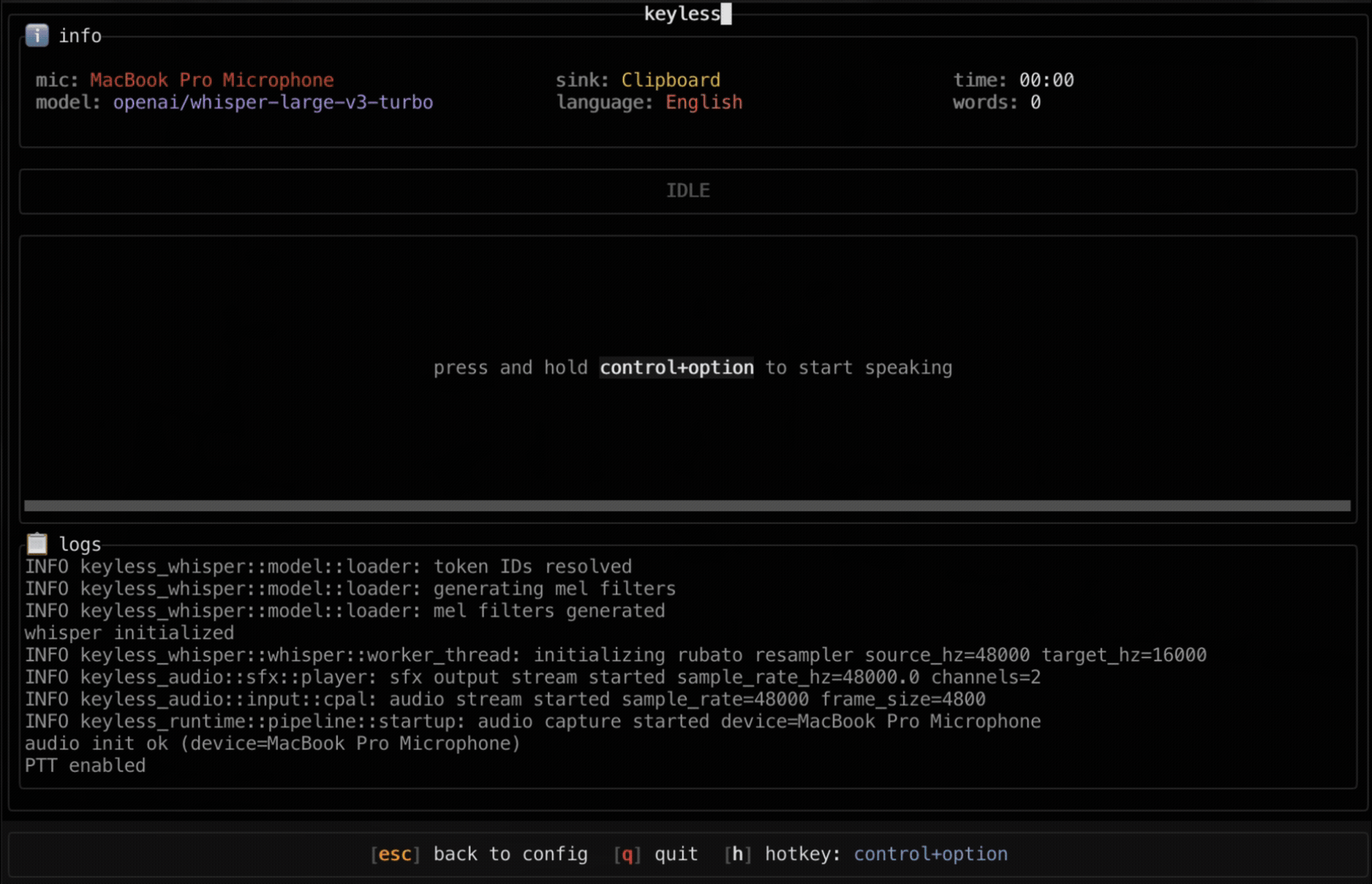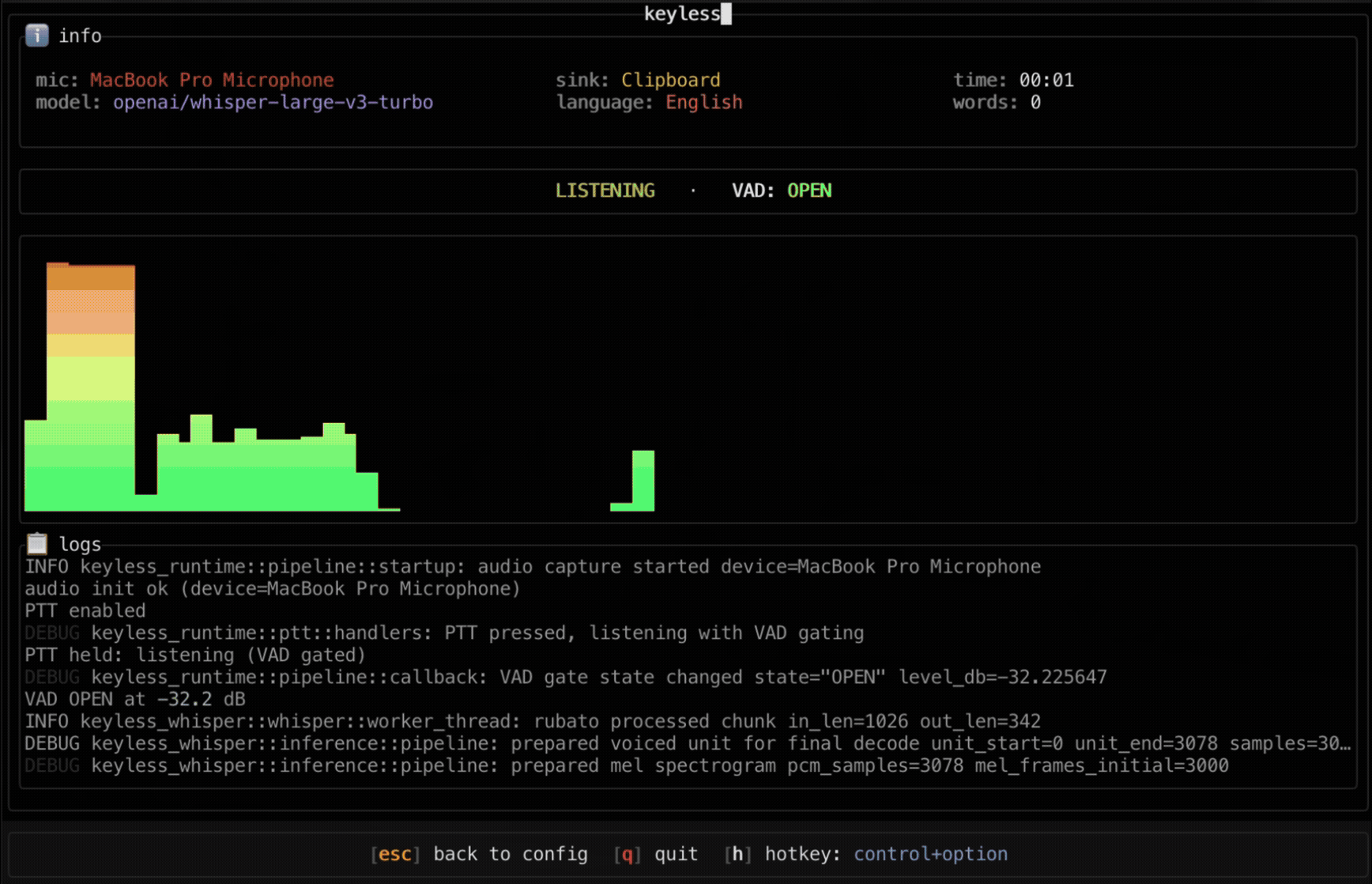
▸ TUI (Terminal) Version
Download binary · Releases
Look for keyless-* assets (not desktop)
# Download from releases page
# Extract and run
./keyless # macOS/Linux
keyless.exe # Windows# Install via Cargo (from git)
# Latest main
cargo install --git https://github.com/hate/keyless --package keyless --locked
# Or pin a release tag
cargo install --git https://github.com/hate/keyless --tag tui-v0.3.0 --package keyless --locked
# Update existing install
cargo install --git https://github.com/hate/keyless --package keyless --locked --force
# Enable CUDA (Linux/Windows with NVIDIA)
cargo install --git https://github.com/hate/keyless --package keyless --locked --features cudaNote: CUDA is optional; add --features cuda on NVIDIA systems with the CUDA toolkit. macOS Metal is automatic.
# Build from source
git clone https://github.com/hate/keyless.git
cd keyless
cargo build --release
./target/release/keylessFirst run: Downloads Whisper model. Usage: Press Control+Option (configurable) to start dictating.
$ ls features/
▸ Privacy-First Architecture
- • 100% local processing
- • No cloud, no API keys
- • All data stays on device
- • Open-source & auditable
▸ Real-Time Transcription
- • Live preview while speaking
- • Push-to-talk control
- • Computed final transcription
- • Multilingual (99 languages)
▸ Smart Quality
- • No-speech detection
- • Temperature fallback decoding
- • Auto language detection
- • Quality metrics tracking
▸ Performance Optimized
- • GPU acceleration (Metal/CUDA)
- • Quantized model support
- • Auto mic rate (device default; prefers 48 kHz; caps high rates)
- • High-quality resampling (rubato, FFT‑based)
$ cat motivation.txt
Built to create a fast, private dictation workflow using the fewest dependencies possible, entirely in Rust. Audio capture, ML inference, concurrency orchestration, and both a responsive terminal UI and modern desktop app—all local, no accounts required.